Доступ к базе данных проекта
Предварительный (№16) вариант.
Это 16 версия данной статьи. Последняя версия - 24. Имеется в виду, что после 20 мая 1999г данный документ больше не обновляется.
В данной статье рассматривается традиционный подход к автоматизации управления версиями файлов и модулей с целью повышения эффективности коллективной разработки проектов. Особенно полезным он оказался для проектов, содержащих большое число текстовых файлов, что характерно для разработки программ и крупных Web-сайтов. Приведен также сравнительный обзор некоторых популярных программных средств, применяемых в этих целях.
Введение
При разработке коллективом программистов крупного программного проекта рано или поздно возникает проблема эффективной синхронизации изменений, параллельно вносимых в проект разными разработчиками. Объем текста и данных, структурная архитектура проекта, количество занятых разработчиков, способы их общения, темпы разработки - все эти факторы имеют сильное воздействие на эффективность используемых методов синхронизации изменений.
Различные коллективы программистов по-разному решают эту проблему. Некоторые предпочитают модель разработки, при которой рабочие множества файлов большинства программистов не пересекаются, а руководитель проекта занимается планированием работы программистов и объединением результатов их труда. Для проектов небольшого размера такой подход является вполне допустимым, но при большом числе программистов и сжатых сроках реализации проекта он становится неприемлем. Затраты времени на планирование работ и объединение результатов труда программистов растут с большой скоростью, в результате чего руководитель проекта становится тормозящим звеном в технологической цепочке.
Единственный выход – разрешить каждому программисту модифицировать код в той части проекта, которая является объектом его работы. При этом, правда, возникает проблема синхронизации изменений, внесенных одновременно разными программистами в один и тот же файл. Конечно, каждый может вручную помещать в проект измененные им файлы, стараясь при этом не уничтожить изменения своих коллег (что удается не всегда), однако на это уходит значительное количество времени. Таким образом, возникает потребность в ПО контроля и объединения версий.
Во время разработки любого проекта необходимым действием является регулярное сохранение предыдущих версий файлов (backup) с возможностью быстрого их восстановления. Необходимость в этом возникает, в частности, при поиске причины появления новых ошибок между версиями (bug tracking). Самым простым решением является использование для этих целей мощного архиватора, стримера и т.п., но их работа при больших размерах проекта может растянуться на часы. Более того, часто желательно сохранять каждую версию каждого файла, снабжая ее для избежания путаницы комментарием: кто изменил этот файл и зачем. Для этих целей используются системы контроля версий (Version Control Systems).
Нередко при одновременной разработке нескольких программ возникает необходимость использовать одни и те же компоненты исходного кода, такие как, например, элементы интерфейса, в разных проектах одновременно. При разработке долгосрочного проекта часто приходится выпускать модифицированные версии программы или даже семейства таких версий - при этом часть исходных файлов, начиная с какого-то момента, изменяется (или наоборот не изменяется) независимо от основной их версии. Такая ситуация типична для случая, когда необходимо исправление мелких ошибок в одной из предыдущих версий продукта, в то время как новая версия еще не готова к использованию. Скорее всего, эти исправления позднее придется влить в основную ветвь проекта. Поддержка такого ветвления версий (branching) вручную является весьма затруднительной задачей.
Следовательно, наиболее приемлемым вариантом для разработчика является ПО, умеющее как объединять различные версии текста программы, так и вести полную историю изменений сразу нескольких проектов с совместным использованием общих компонентов в разных проектах (sharing) и ветвлением.
Вариантов структуры и организации коллективной разработки программ, конечно же, много, но из них можно выделить четыре основных:
Существующие решения и критерии их сравнения
Контроль и объединение версий исходного кода ПО – достаточно трудная задача, однако, предлагаемые существующими средствами коллективной разработки способы облегчения и автоматизации этого процесса основаны на достаточно очевидных идеях. Все сводится к ведению базы данных (обычно общей для всех разработчиков), содержащей историю изменений в каждом файле проекта, и автоматизации следующих операций:
Подробно будет описано функционирование Windows 95/NT – версий CVS и Microsoft Visual Source Safe, а также весьма оригинальной программы Code CO-OP. UNIX-версии, которые имеет большинство средств коллективной разработки (кроме появившихся совсем недавно, как Code Co-op), в данной статье не явно упоминаться не будут ввиду отсутствия у них графического интерфейса, а интерфейс командной строки такой же, как и в версиях для Windows. Тем не менее, из соображений безопасности рекомендую размещать базу данных проекта на UNIX-сервере.
Стоит отметить, что некоторые СКР, построенные на основе более примитивных систем контроля версий, используют их средства управления файлами. CVS, к примеру, при хранении своей базы данных использует RCS (Revision Control System), которая, в свою очередь, является обычной системой контроля версий.
Проект как объект коллективной работы
Каждый проект представляет собой набор директорий и файлов различных типов, находящихся
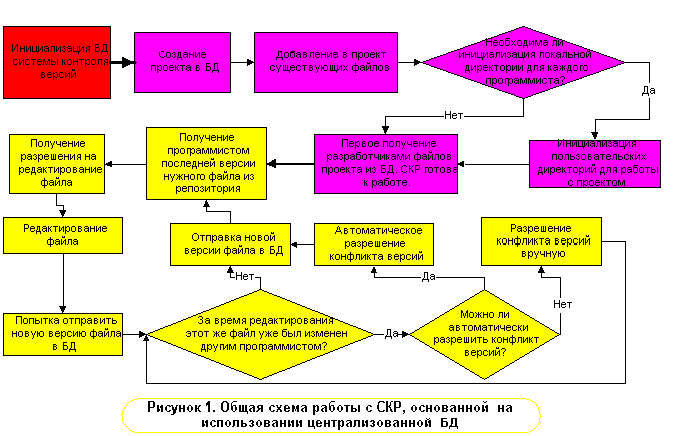
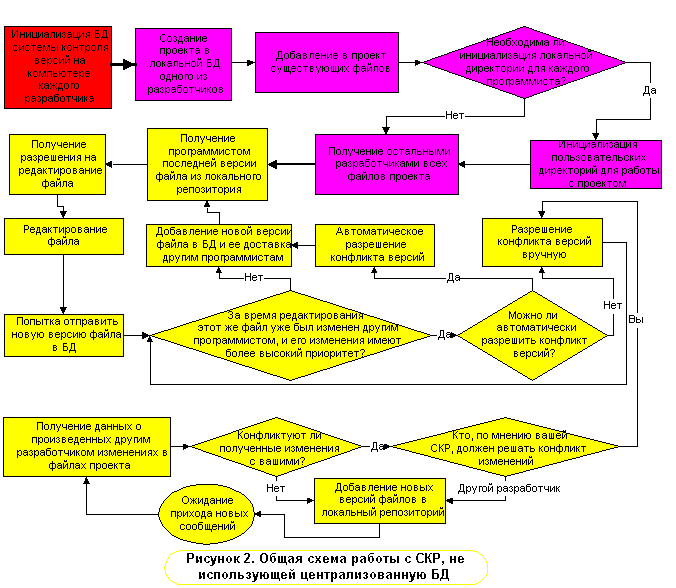
Итак, перед тем, как приступить к работе с проектом, нужно создать его базу данных – это делает администратор проекта. Затем все участники проекта получают, используя средства своей системы контроля версий, с сервера необходимые файлы на свой локальный диск по мере необходимости – при этом обычно они могут получить любую из предыдущих версий, а также по необходимости описание сделанных там изменений. Если данная СКР не основана на использовании центральной базы данных на сервере, то изначальный набор файлов проекта разработчики получают у администратора, а затем уже работают со своей локальной базой данных.
В процессе работы программист должен регулярно проверять (средствами СКР), какие изменения были внесены в исходный код его коллегами. Внеся в файлы нужные изменения, он должен отправить их обратно на сервер (или другим разработчикам, чтобы обновить их локальные базы данных). Именно на этом этапе системы коллективной разработки производят свою основную работу: находят изменения в файле по сравнению с той его версией, которая была до редактирования, проверяют, изменил ли кто другой этот файл на сервере (обрабатывая, в случае необходимости, конфликт версий), и предлагают программисту описать внесенные изменения.
Рассматриваемые средства
Хранение файлов в базе данных проекта
CVS и VSS сохраняют в своей базе данных всю историю изменений проекта, так что в любой момент времени человек может восстановить одну из предыдущих версий какого – либо файла или всего проекта.
COOP также ведет историю всех изменений проекта, в основном с целью синхронизации с другими разработчиками, и предоставляет пользователю возможность получить из локальной базы данных любую из имеющихся в ней версий нужного файла. Новые версии сохраняются в базе данных в виде последовательности так называемых скриптов – записей об изменениях файлов.
Если на одном из этапов разработки проекта из него удаляется какой-либо файл, соответствующая этому файлу запись в базе данных не удаляется (т.е. просто файл отмечается как удаленный в данной версии).
Практически все СКР хранят файлы в базе данных в виде последовательности изменений – от новой версии файла к старой, - а не каждую версию каждого файла целиком. Это значительно сокращает размер БД.
Доступ к базе данных проекта
Процесс редактирования файла, входящего в состав проекта, работа с которым происходит с использованием средств коллективной разработки, состоит из следующих действий:
Создание базы данных проекта
на сервере и инициализация работы с ней
на машине участника проекта
В CVS и VSS все версии программного проекта содержатся в одной централизованной базе данных, которая и обеспечивает синхронную разработку. Начальную настройку этой базы данных осуществляет обычно участник проекта с правами администратора. Она включает в себя создание исходного набора файлов на сервере, содержащих различные настройки (в том числе и касающиеся прав доступа к этому репозиторию для участников проекта), а также файлы, в которые будет записываться информация о содержимом этой базы данных.
Создать в репозитории новый проект имеет право любой программист, который имеет право туда писать. Проект можно, конечно, создать пустым, но по умолчанию CVS добавит туда все файлы из текущей директории, поскольку команды создания просто пустого проекта в CVS нет. В VSS есть отдельные команды создания пустого проекта и импортирования дерева файлов и директорий в новый проект.
В Code Co-op необходимо создавать только локальную базу данных. Возможно как создание пустого проекта, так и импортирование уже имеющихся файлов в новый проект.
В принципе, в большинстве СКР, снабженных визуальным интерфейсом, можно получить файл из репозитория на редактирование в любую директорию. В CVS же, например, приходится вызывать команду cvs checkout, которая производит получение данного модуля (подпроекта) из базы данных и инициализацию той директории, в которую он будет записан. Каждому модулю соответствует любая директория, в которой есть поддиректория “CVS” с информацией о соответствии локальных файлов файлам репозитория (и их версиях). Большинство команд CVS можно выполнить только в таким образом проинициализированных директориях. Один программист может безболезненно работать с несколькими различными репозиториями – в зависимости, например, от текущей директории.
Работа с проектом после завершения всех настроек
Каждый программист может получить (check out) из базы данных любую версию одного или нескольких файлов (в т.ч. целиком весь проект), а также отправить в БД новые версии измененных им файлов (check in).
Новая версия файла может отправиться в базу данных VSS только в случае, когда перед редактированием самая последняя версия этого файла была получена из БД путем операции check out, во время которой в базе данных VSS, в частности, отмечается, что данный файл редактируется данным программистом. Таким образом, изменения, сделанные в файле, который не был отмечен, как “checked out”, не смогут попасть в БД проекта (однако вероятность таких случаев минимальна, если для вызова файлов проекта на редактирование использовать графический интерфейс VSS или программ, в которые он интегрирован). Благодаря визуальному интерфейсу VSS, все программисты, работающие с данным проектом, сразу увидят, что указанный файл “принят” кем-либо из них. При получении файла на редактирование его можно заблокировать, т.е. запретить его редактирование другими программистами. Администратор проекта может включить автоматическую блокировку редактируемых текстовых файлов (в противном случае каждый текстовый файл разработчик может заблокировать по желанию). Бинарные же файлы блокируются всегда.
CVS не предоставляет возможности отследить, кто и когда запросил из базы данных какой-либо файл. Тем не менее, узнать о том, что файл редактируется другим человеком, можно, при помощи команды “cvs watch” отлавливая вызовы команды cvs edit, производимые другими программистами. Разумеется, способ заставить вызывать “cvs edit” традиционный: после очередного приема файла из репозитория у каждого программиста на локальные копии “наблюдаемых” файлов будет установлен атрибут read only (или сняты права на запись в них под UNIX’ом). Выполнение “cvs edit” разрешит запись в файл, а “cvs unedit” снова запретит (правда, некоторые редакторы и сами умеют снимать и устанавливать разрешение на запись, сообщая об этом пользователю, когда тот уже завершил редактирование и хочет сохранить изменения). Одна из возможных неприятностей: если кто-то начал редактировать файл до подачи вами команды watch, и пока не спешит заканчивать, то вы об этом можете узнать слишком поздно. Тем не менее, несмотря на указанные недостатки, данная тактика наиболее приемлема в условиях работы в режиме командной строки без графического интерфейса. Запретить другим запись любого нужного ему файла в базу данных пользователь CVS может средствами команд RCS (cvs admin -l). Таким образом, при работе с CVS разработчик, в принципе, не обязан проверять, последнюю ли версию того или иного файла он редактирует, и может ли он вообще редактировать этот файл, - но несоблюдение правил работы с CVS'ом приводит к дополнительной потере времени, и достаточно быстро человек приучается регулярно выполнять команду cvs update.
Пользователь COOP, только что присоединившийся к проекту, получает полную копию всех файлов у администратора – человека, который начал разработку проекта в COOP раньше других разработчиков. Все файлы проекта у него хранятся в выбранной им директории, причем на них устанавливается атрибут read only. При этом при операции check out COOP просто снимает атрибут read only с выбранного файла. По окончании работы с файлом при операции check in COOP возвращает на файл атрибут “только для чтения” и создает сообщение - скрипт (script) о том, какие изменения были внесены в этот файл, которое рассылается (обычно по электронной почте) всем участникам проекта, список которых программист получает у администратора. Пришедшие по почте (или иным путем) скрипты об изменениях, сделанных другими программистами, вручную или автоматически передаются запущенной программе COOP, которая изменяет локальные копии файлов в соответствии с содержимым этих скриптов. Все скрипты, которые создаются на машине данного разработчика или приходят к нему по почте, сохраняются в локальной базе данных проекта, благодаря чему программист может легко восстановить любую версию любого файла, проходившего через его руки. Таким образом, все основные действия над файлами производятся программистом в локальной копии проекта. Ни о какой блокировке файла для эксклюзивного редактирования речи не идет, так как время оповещения об этом всех участников разработки не определено.
Разрешение конфликтов изменений, внесенных в текстовый файл параллельно разными разработчиками
Итак, два или более человека намеренно или ненамеренно одновременно отредактировали одну и ту же версию одного и того же файла, а затем один за другим решили отправить его в базу данных. Как в CVS, так и в VSS, у того, кто это сделает первым, никаких проблем не возникнет, и его локальная копия данного файла будет доставлена в базу данных в качестве последней версии. Второму же будет сказано, что его изменения в этом файле не совпадают с изменениями, внесенными первым (если это действительно так).
На стадии, предшествующей отправке
такого файла в БД проекта (cvs update) CVS, если
не в состоянии сама соединить версии, вставляет отчет о конфликтующих изменениях
в данный файл так, чтобы можно было разрешить возникший конфликт при помощи
удаления лишних строк. Например, если один добавил в файл MLK67W.CPP строчку
// We finished!!!
и отправит в базу данных, а второй в то же место напишет
// We finally crashed!!!!!!,
то после команды cvs update он увидит
на месте своего изменения следующее:
| ...
} while(crashControl1-crashControl2<=6 && crashControl2==0x3abcdef3); <<<<<<< MLK67W.CPP // We finally crashed!!!!!! ======= // We finished!!! >>>>>>> 1.4 if (ConsoleOutFile && cofl) fclose(cofl); ... |
Если VSS на этапе отправки такого файла в БД решит, что изменения, сделанные вторым программистом, можно автоматически объединить с изменениями первого, он об этом напишет и предложит просто отправить объединенный файл в базу данных. В противном случае будет вызвана программа визуального объединения двух текстовых файлов – достаточно удобный инструмент. Правда, есть в VSS одна ошибка: если один программист решает конфликт в каком-либо файле в течение длительного времени, то до окончания этой работы его коллега не сможет отправить в репозиторий свою версию того же файла. Проведя все стадии объединения версий файла, последний увидит сообщение вроде “file ... is already open” – тогда ему придется подождать и начать все заново. К счастью, такие случаи имеют место нечасто, объединение конфликтующих версий файла обычно проходит быстро, да и следующая версия VSS уже не за горами.
COOP действует в таких ситуациях следующим образом: если от другого разработчика пришел скрипт с изменениями файла, который вы редактируете, то после завершения редактирования после команды check-in ваши изменения будут помечены, как конфликтующие, и будет вызвана программа разрешения конфликта версий, которая либо сама сможет объединить две эти версии, либо вызовет утилиту визуального объединения. Если два программиста одновременно рассылают скрипт с изменениями одного и того же файла, то один из двух конкурирующих скриптов будет отменен (сразу у всех участников проекта), и тому, чей скрипт отменили, придется заняться решением конфликтов, после чего попытаться послать скрипт снова. Есть одна неприятность, – когда скрипт, из-за прихода которого нетривиально решается конфликт версий, отменяется другим скриптом, пришедшим значительно позже вследствие медленной работы почты, т.е. большое количество времени оказывается потраченным зря. Но это случается все-таки достаточно редко, так что не приведет к особым затратам времени. Конечно, гипотетически может сложиться такая ситуация, когда скрипты одного человека будут отменены десяток раз подряд, – но это маловероятно, в т.ч. потому, что алгоритм выбора отменяемого скрипта достаточно продуман.
Итак, что же все программы, обладающие
такой функциональной возможностью, считают конфликтом версий без
возможности автоматического объединения? В процессе сравнения трех версий
одного текстового файла (исходной и двух новых) выделяются группы последовательно
идущих строк, в которых локализуются изменения файлов. Если изменения в
первой и второй новых версиях файла (по сравнению с базовой) не пересекаются,
совпадают или включают друг друга, то конфликт версий разрешается автоматически.
В противном случае возникает текстуальный конфликт версий, который приходится
вручную разрешать разработчику. Конечно, разные алгоритмы сравнения файлов
в этом случае дают слегка отличающиеся результаты, но это различие мало
сказывается на работе программиста. Несомненно, однако, то, что всегда
можно внести в файлы такие изменения, которые при автоматическом слиянии
будут проинтерпретированы неверно, - но такое случается очень редко.
Работа с бинарными файлами.
Системы коллективной разработки традиционно делят все файлы на два типа: текстовый и бинарный, причем при работе с бинарными файлами имеются значительные ограничения:
В этой связи CVS предоставляет следующие возможности: присвоение файлу или группе файлов (последней версии) текстового имени версии; присвоение последним на момент времени, выбранный пользователем, версиям файлов, текстового имени версии; присвоение каждой версии файла (файлов) числового значения версии, причем последнее число (младший номер версии) автоматически увеличивается на 1 от версии к версии.
VSS может присвоить текстовое имя версии любой версии проекта (версия проекта меняется после очередного изменения хотя бы одного файла в нем) и любой версии файла, производит автоматическое увеличение доступных пользователю номеров версий файлов и всего проекта. Его визуальные средства позволяют просмотреть историю изменений проекта и получить какую-либо версию любого файла (или проекта целиком) как по номеру версии, так и по ее имени (если есть).
COOP не предоставляет возможности текстового или какого-либо еще именования версий в силу объективных причин (отсутствия сервера).
Большинство систем коллективной разработки, работа которых основана на использовании БД на сервере, позволяет одному и тому же файлу принадлежать сразу нескольким проектам (хранящимся в одной базе данных) одновременно. Подпроектом является проект, все файлы которого содержатся в другом проекте, хотя многие программы считают подпроектами только поддиректории в дереве проекта. Способы задания подпроектов и совместного использования файлов между проектами могут различаться очень сильно.
В CVS база данных вообще не разделена на проекты - она представляет собой единое дерево файлов и директорий. Благодаря файлу modules можно, тем не менее, легко манипулировать целыми деревьями из файлов и директорий, фактически расположенных в разных частях репозитория, используя одно логическое имя.
В VSS база данных разделена по проектам, но в любой момент файл из одного проекта можно добавить в другой средствами визуального интерфейса - при этом разработчики обоих проектов будут без проблем делить (share) этот файл. Проект в VSS представляет собой просто структуру из файлов и директорий, которые на локальном диске хранятся в выбранной пользователем директории. Каждая поддиректория в дереве проекта считается подпроектом, для которого, соответственно, можно определить свою, независимую от директории "родителя", рабочую директорию на локальном диске программиста. Единственное свойство подпроектов, выделяющее их из других проектов - наличие возможности располагать все подпроекты в соответствующих поддиректориях домашней директории родительского проекта при рекурсивном получении родительского проекта с сервера.
COOP не поддерживает проекты и подпроекты, также как и использование одного и того же файла в разных проектах.
Иногда бывает необходимо вести разработку параллельно нескольких версий проекта, например, после публичного выпуска одной из версий в ней приходится исправлять ошибки, в то время как последняя версия проекта находится на промежуточной стадии разработки и непригодна для использования.
В CVS создание ветви (branch) версий исходного кода производится командой rtag с ключом -b - при этом программист дает этой ветви текстовое имя, которое удобно использовать при получении файлов из репозитория. Следует отметить, что этой командой можно выделить любой файл или группу файлов.
В VSS какую - либо из предыдущих версий проекта можно скопировать в отдельный проект - и с этим новым проектом уже работать. Надо сказать, что хотя VSS и создает в своей БД отдельную копию этого проекта, он запоминает, что данные файлы все же являются другими версиями исходных, что дает возможность быстрого слияния этих ветвей. Эту операцию можно произвести и над отдельными файлами, если их сначала сделать общими для двух проектов, а затем применить команду branch.
В системе Code Co-op можно только выделить текущую версию проекта в отдельный проект, и разрабатывать ее независимо.
При использовании средств коллективной разработки совместно с другими средствами разработчика, имеющими визуальный интерфейс (редакторы, например, или среды разработки) часто становится неудобно постоянно переключать задачи или вызывать каждый раз нужные программы вручную. Таким образом, встает вопрос о возможности:
VSS позволяет переопределить, во первых, редактор для ввода сообщений, во вторых, программы просмотра и редактирования текстовых файлов, вызываемые непосредственно из визуальной оболочки VSS. Для файлов других типов вызываются редакторы, зарегистрированные в используемой операционной системе (обычно Windows или MacOS). Все производимые пользователем команды могут быть продублированы из командной строки, что делает возможной интеграцию с другим ПО. Использование внешних средств сравнения и объединения файлов невозможно.
COOP не имеет интерфейса командной строки и возможности использования каких-либо внешних программ, кроме редакторов.
Другие средства разработки.
ллл[]
Завершающая
глава это выводы и практические рекомендации.
Также
можно рассмотреть возможные направления для развития в данной области –
это “на ура”.